An introduction to genetic algorithms. An example on travelling salesman problem (link to source-code included)
Wait what?
Today, when we come up with something we do not quite understand we google it. Usually, if your search is not something like “Why are softballs so hard?” there is somewhere a Wikipedia article about that. Let’s see, what does Wikipedia say about genetic alogirhtm:
In computer science and operations research, a genetic algorithm (GA) is a metaheuristic inspired by the process of natural selection that belongs to the larger class of evolutionary algorithms (EA). Genetic algorithms are commonly used to generate high-quality solutions to optimization and search problems by relying on bio-inspired operators such as mutation, crossover and selection.
Not quite informative. I will try to make it simpler. Imagaine that you are an agornomist who lives in the far north where apple doesn’t grow. In order to have apples to grow, you need frost resistant apples. To get them, you can either plant many apple trees and hope that some of them survive, or you can try to breed new apple species from the existing ones. From produced apple species you will then select the best ones and breed even better ones. Finally, you will have an apple garden.
Bilogical inspiration
You probably remember from your school times what is a cell (HINT: Cell is a building block of all living beings).
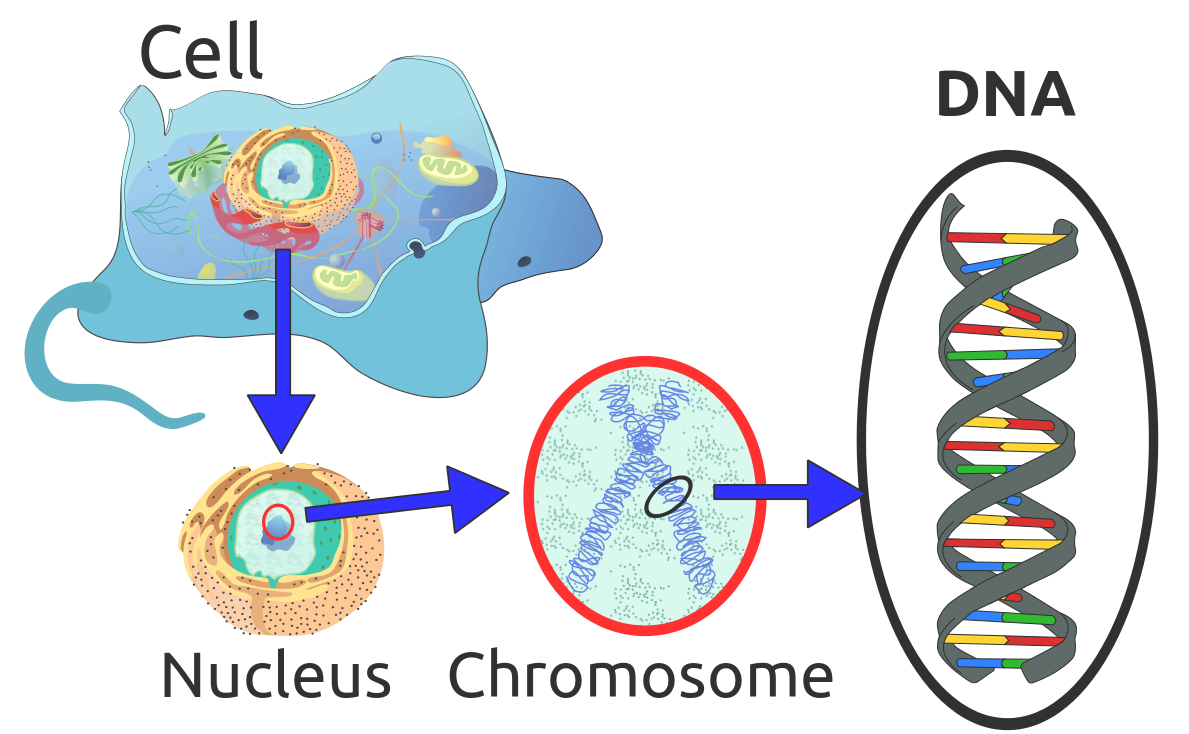
Every cell consists of chromosomes and every chromosome has DNA. This DNA has the main informations about the specific trail
What is genetic algorithm?
Now let’s recall our example above about the apples. Which steps we should take?
- First, we should define initial apple species we want to use.
- We should define a function to see if they are suitable or not. It will be simple now. Died means bad, survived means good.
- Select the ones that are good and breed new species from them.
- Repeat the step 2 and evaluate the good again.
- Rebreed new species
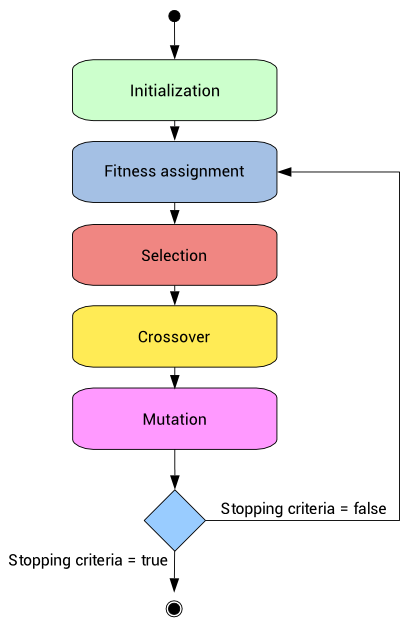
The process repeats. These are the basics of genetic algorithms. It mimics the evolution in nature. In general terms, the process looks like this:
Learning while doing
My personal approach to learn something is doing it. Let’s take a look at one of the very simple-structured, old, yet hard to solve problems, travelling salesman problem. This problem is about a simple question: Given the n number of cities, calculate the route which will path through all of them while having the minimum distance to cover. Returning to start point may and might not be optional.
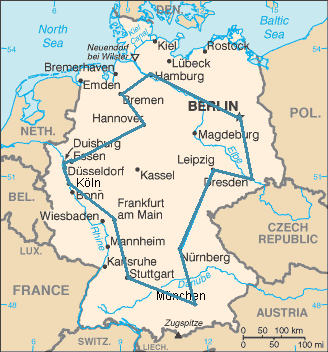
For example, this optimal route is going through the 15 biggest cities of Germany. This is the shortest possible route from all 43 589 145 600 (~ 43.6 billion) possibilities (Source: Wikipedia).
At first sight, it might seem that this problem is not very hard as I mentioned. Let’s say, we have three cities: A, B, and C. The possible solutions would be:
- ABC
- ACB
- BAC
- BCA
- CAB
- CBA
Overall, 6 possible answers. Speaking mathematically, given n number of cities, there can be n! possibilities. That’s quite a lot. If there are 100 cities, the possibilities are more than the atoms in the universe!
So, how we solve such problem? Now, genetic algorithm comes to rescue. It will have these stages:
- Creation of initial population
- Calculating the fitness of each genome (in our case, it will be a route)
- Imitaion of natural selection:
- Elitism
- Roulette
- Creation of the next generation:
- Crossover
- Mutation
- Repetition
Creation of initial population
Here we randomly create routes for the first generation which will be our initial population. Then, we move to the second stage.
Calculating the fitness of each genome
Here we calculate the fitness of each genome in initial population. In our case it means the distance of the route. It will be calculated as Manhattan distance between every pair of cities. The inversed distance will become our fitness value.
Imitation of natural selection: Elitism vs Roulette
Elitism means that, the top N best genomes will automatically be present also in the next generation. I will use another approach, the roulette selection. It puts every genome onto the roulette and places them according their fitness values. Then it randomly selects the given number of genomes randomly according to their fitness.
Creation of the next generation: Crossover and mutation
After having the genomes which will be present in the next generation, we randomly make crossovers between the routes. Like with humans, the child genome of two parents will have half of the DNA from father and half from the mother. In our case, we will keep the first part of the route and replace the second part from the another route in the order of appearance. This process will be repeated until the next population has enough genomes. Then, according the mutation probability, random mutation will occur like in the nature. Mutation will randomly swap two elements of the genome (route).
Repetition
This stages will be repeated until we reach the maximum number of generations. With every generation, the optimal route will become shorter and shorter.
Pros and cons of genetic algorithms
Some advantages of genetic algorithms are:
- They usually perform better than traditional feature selection techniques.
- Genetic algorithms can manage data sets with many features.
- They don’t need specific knowledge about the problem under study.
- These algorithms can be easily paralelized in computer clusters.
There are also some disadvantages:
- Genetic Algorithms might be very expensive in computational terms, since evaluation of each individual requires building a predictive model.
- These algorithms can take a long time to converge, since they have a stochastic nature.
You can find my own implementation of the genetic algorithm in solving travelling salesman problem on my github. It is written in Python and uses only the default Python libraries.
In conclusion, genetic algorithms can be used for selecting the best subset of the model/solution, but they are computationally intensive and require more time than other combinatorial optimization techniques. Depending on the task, they can be your way to go.